Python Colaboratory Ⅴ
CNN (Convolutional Neural Network)概要
ここまで、RNN や LSTM で時系列デ-タを予測することについて勉強してきました。
ここからは CNN(畳込みニューラルネットワーク)で時系列デ-タ予測していきたいと思います。
CNN は画像認識で高い評価を得ています。
これを時系列デ-タ予測に適応していきます。
「畳込み」とは、スライドさせながら適用し特徴を絞っていく分析方法とされています。
局所的な領域の特徴を抽出することができます。
畳込み演算をすると特徴抽出ができるとされます。
具体的には、時系列データから移動平均を計算することで、畳込み演算を行ないます。
個々のデータだけを見たときには、ノイズが多くて、データの全体の傾向を把握できませんが
連続したいくつかのデータを同時に見たときには、何らかの傾向を見出せます。
時系列データ解析で、移動平均を求めることが、データのノイズを減らし、データ全体の傾向
を把握する手段となります。
時系列データの移動平均を求める演算は、畳込み演算とよぶことができます。
例えば、3日間平均を求める場合は、長さ3で、要素が(1/3, 1/3, 1/3)のフィルタを
時系列全体にかけて、時系列を畳込みます。
計算例を図示すると、下記のようになります。
畳込み演算の進行
畳込み演算がどのように進むのか上図をもとに具体的に説明します。
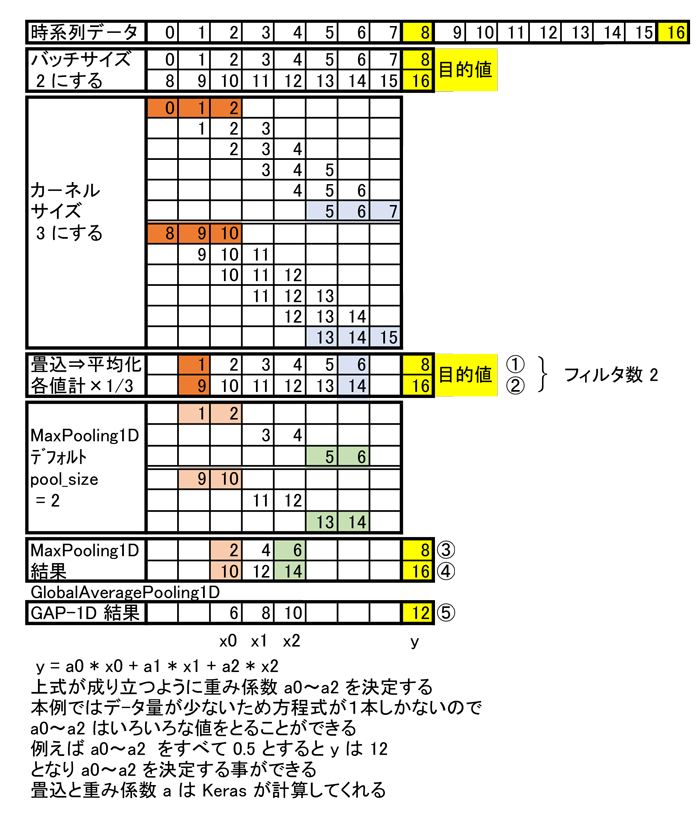
- 時系列デ-タ
例として
0,1,2,3,4・・・・・13,14,15,16
の 17個のデ-タがあったとします。
これをバッチサイズ8個のデ-タ列に並び換えます。
0,1, 2, 3, 4, 5, 6, 7 目的値 8 ・・(イ)
8,9,10,11,12,13,14,15 目的値 16 ・・(ロ)
に整列させます。 - フィルタをかける
例としてカ-ネルサイズ3でフィルタをかけます。
(イ)の行の最初のデ-タ3個にフィルタをかけ
0,1,2
を取り出します。
これを平均化した値 1 が畳込んだデ-タとなります。
具体的に言うと、時系列データの最初の 3 要素それぞれに 1/3 をかけ その和を出力します。
今回の例では
0×(1/3) + 1×(1/3) + 2×(1/3) = 1
となります。
次に(イ)の行の2番目からのデ-タ3個にフィルタをかけ
1,2,3
を取り出します。
これを平均化した値 2 が畳込んだデ-タとなります。
これを(イ)の行の最後まで繰返します。
これで(イ)の行のフィルタ結果①ができ上がりました。
同じことを(ロ)の行についても行ないます。
畳込んだ平均化されたデ-タは
(イ)行 1, 2, 3, 4, 5, 6 8⇒6 個に圧縮
(ロ)行 9,10,11,12,13,14 8⇒6 個に圧縮
となりいずれも、8⇒6 個にデ-タ数が圧縮されました。
そしてその特徴は破損することなく残されています。
また、①と②の二つのフィルタ結果が出力されたので、フィルタ数は 2 となります。 - 圧縮数
どのぐらい圧縮されたのかみてみましょう。
フィルタで畳込んだ後の要素数 Y は
W:時系列データの長さ
H:カーネルサイズ
とすると
Y = W - 2 * ( H / 2 ) + 1
となります。
ここでは
W = 8
H = 3
ですので
Y = 8 - 2 * ( 3 / 2 ) + 1
= 6
となります。
ちなみに、カーネルサイズを大きくし
H = 7 とすると Y = 2
H = 8 とすると Y = 1
となり、大きく圧縮することができます。 - 最大値プ-リング
①②の特徴量マップをさらにダウンサイズするため最大値プ-リング演算を行ないます。
最大値プ-リングをすると各位置の領域内での最大値」が出力されます。
pool_size がマックスプーリングを適用する領域のサイズです。
今回は pool_size は 2 とします。
ただ、MaxPooling1D はデフォルトで pool_size が 2 に設定されているようです。
例えば①を pool_size = 2 で最大値プ-リングしてみます。
それぞれ 1,2 3,4 5,6 の最大を抽出すると 2,4,6 となり、その結果は③のようになります。
同様に、②も最大値プ-リングすると④のようになり いずれもその特徴は破損することなく圧縮されて残されています。 - GlobalAveragePooling1D
時系列データのためのグローバルな平均プーリング演算を行ないます。
次元ごとに平均をとったものが出力となります。
よって、MaxPooling1D にはあった pool_size, strides のような引数はありません。 GlobalAveragePooling1D レイヤーの出力は、元のレイヤーの出力と比べてコンパクトになりますが この情報圧縮により前後関係が失われることがあります。
ここはちょっと困ったところです。 - 重み係数
畳込まれたデ-タが抽出されました。
このデ-タには特徴が圧縮されています。
よって⑤のフィルタ結果を使用して重み
a0, a1, a2
を計算すればよいことになります。
y = a0*x0 + a1*x1 + a2*x2
から計算することができます。
今回の例では
⑤より
x0 = 6, x1 = 8, x2 = 10
y = 12
ですから
一つの方程式を作る事ができます。
デ-タ不足ですが、適当に a0, a1, a2 を決めれば この方程式を満足する解を決定することができます。
例えば、a0~a2 をすべて 0.5 とすると
⑤行の y の値は 12 になり、目的値 12 と同じになり a0~a2 を決定することができます。
ただ、これらの畳込演算と重み係数の計算は Keras が勝手に計算してくれますので、 気にすることはありません。
引き続き、CNN を Keras で実現していきます。
70VPS に戻る




