Python Selenium Web 自動操作
Selenium で Google 検索開始
ここまでで、Selenium で Google 検索を開始する準備ができました。
引き続き Google 検索を行なっていきます。
検索語ここでは「Python」を入力して送信します。
まずは、検索語を入力する部分をさがします。
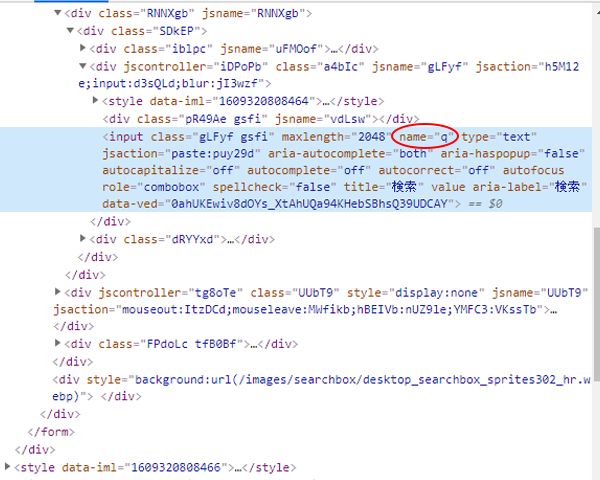
以下は Google トップページの HTML ソースコードを Chrome で表示させたものです。
PC であれば、ブラウザ表示部分を右クリックして「検証」をクリックすると表示可能です。
これを見ると
<input class="・・・・・・・" name="q"・・・・
の部分に検索文字を入力すればよいことがわかります。
よって
input_element = driver.find_element_by_name('q')
input_element.send_keys('Python')
input_element.send_keys(Keys.RETURN)
として検索文字を送信します。
どこに検索文字を入力すればよいのかがわかれば簡単ですね。
Google 検索結果画面の確認
Google 検索結果画面に 'Python' の文字が含まれていることを確認します。
title 部分に'Python' の文字があるので
assert 'Python' in driver.title
で画面が遷移したことを確認できます。
スクリーンショットも撮っておきましょう。
driver.save_screenshot(scsh_name)
scsh_name は
Python Selenium Web 自動操作概要
のなかの「スクリーンショットファイル名準備」
のところで説明しています。
scsh_name = '/home/yamada/public_html/images/' + now_str + '.png'
now_str の例 210120120130
2021年1月20日12時1分30秒の場合
Google 検索結果の表示
検索結果の見つかったタイトル名とその URL を表示します。
Google 検索結果画面の HTML ソースコードは下記のようになっています。
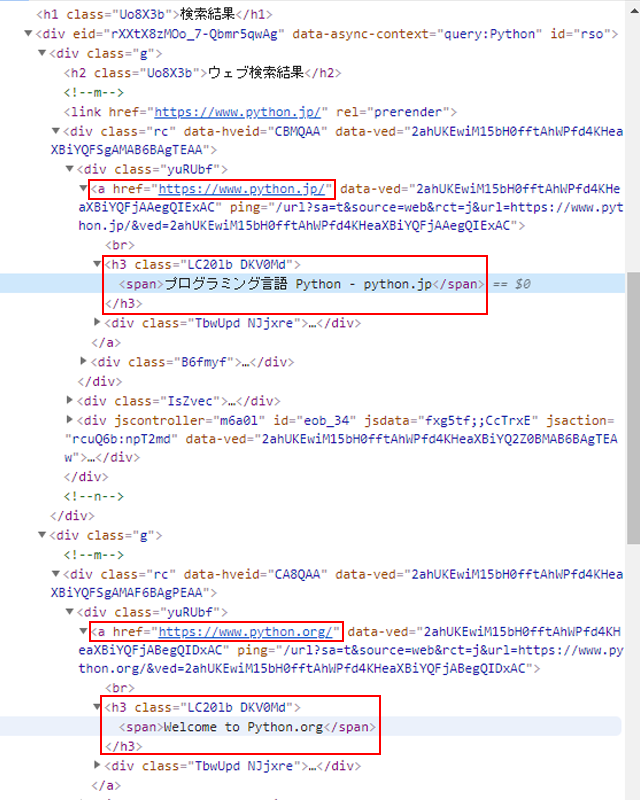
h3 部分に結果タイトル名が
その親要素 a href 部分にその URL があります。
driver.find_elements_by_css_selector('a > h3')
で検索結果のタイトル名とその URL を見つけることができますが、
これは一つだけではありません。
よって for 文でそのすべてを抽出します。
一つの h3 の 'a > h3' の CSS のセレクトできたら、
それに対応する h3 の親要素 a を取得します。
a = h3.find_element_by_xpath('..')
すでに子の h3 は見つかっているのでその親の a 要素を見つけます。
2段階 '..' 戻る必要があります。
1段階 '.' 戻りでは 'href' を見つけることはできません。
後は、
print(h3.text)
print(a.get_attribute('href'))
で表示します。
for 部分をまとめると以下のようになります。
for h3 in driver.find_elements_by_css_selector('a > h3'):
# h3の親要素を取得
a = h3.find_element_by_xpath('..')
print(h3.text)
print(a.get_attribute('href'))
後はブラウザーを終了します。
driver.quit()
Selenium Google 検索ファイル作成まとめ
ここまでで、Selenium Google 検索ファイルを作成することができました。
ファイル内容をまとめて表示します。
from selenium.webdriver import Chrome, ChromeOptions
from selenium.webdriver.common.keys import Keys
import datetime
now = datetime.datetime.now()
now_str = now.strftime('%y%m%d%H%M%S')
scsh_name = '/home/yamada/public_html/images/' + now_str + '.png'
print(scsh_name)
optio = ChromeOptions()
# ヘッドレスモードを有効にする
# optio.headless = True
# ChromeのWebDriverオブジェクトを作成する
driver = Chrome(options=optio)
# Googleのトップ画面を開く。
driver.get('https://www.google.co.jp/')
# タイトルに'Google'が含まれていることを確認
assert 'Google' in driver.title
# 検索語を入力して送信する。
input_element = driver.find_element_by_name('q')
input_element.send_keys('Python')
input_element.send_keys(Keys.RETURN)
# タイトルに'Python'が含まれていることを確認
assert 'Python' in driver.title
# スクリーンショットを撮る
driver.save_screenshot(scsh_name)
# 検索結果を表示
for h3 in driver.find_elements_by_css_selector('a > h3'):
# h3の親要素を取得。
a = h3.find_element_by_xpath('..')
print(h3.text)
print(a.get_attribute('href'))
driver.quit()
# ブラウザー終了
本内容を TeraPad 等で作成したら、ファイル名を適当に
sc_sele_goo.py
として保存します。
文字コ-ドは、UTF-8N
BOM なし
改行コ-ドは、LF
です。
保存先はホスト Wimdows OS の 共有フォルダ c:\vb_public_html にしました。
なお、
c:\vb_public_html
はゲスト OS Ubuntu のなかの
/home/yamada/public_html
とリンクしていて共有フォルダの関係にあります。
詳細は
ユ-ザ-ごとの公開ディレクトリを用意する
を読んでみてください。
ここまでで、Selenium での Google 検索ファイルが完成しました。
引き続き 本ファイル sc_sele_goo.py の動作確認をしていきます。
70VPS に戻る





