Python Colaboratory
RNN の理解-Ⅱ
RNN の理解について説明してきました。
ここまでのところをまとめます。
デ-タ数が 100個とすると下記のようになります。
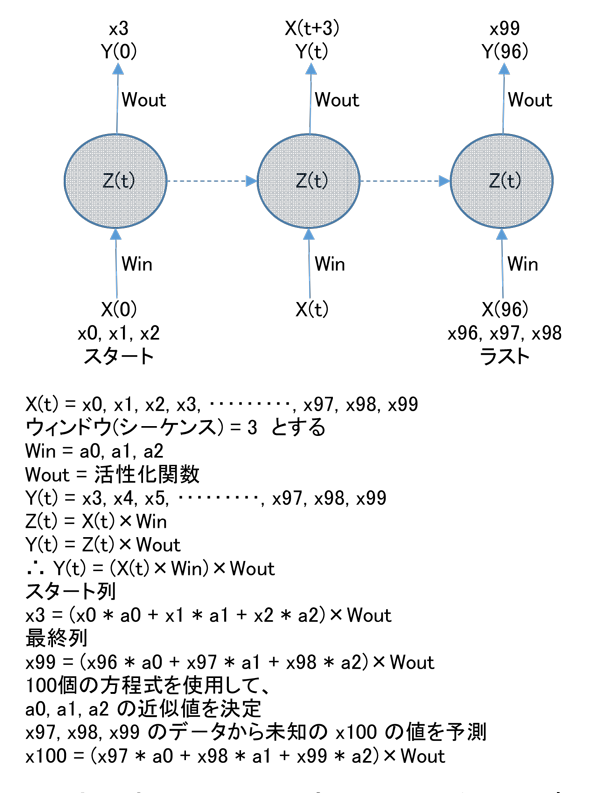
このような解法を勾配降下法(Gradient Descent)と呼ぶようです。
ただデ-タ数が多くなると計算時間がかかりすぎるなどの問題点もあり、
確率的勾配降下法(Stochastic Gradient Descent)
なる方法も考案されています。
デ-タの前処理
Keras を使ってRNN による予測を行なう場合、Keras 自身が理解できるようにデ-タを前処理する必要があります。
keras.utils.timeseries_dataset_from_array メソッドを使用すると前処理ができます。
これがなにをするのか理解するために、簡単な例で説明します。
大まかに言うとこの関数に時系列デ-タの配列を渡すと、元の時系列から抽出されたウィンドウ(シ-ケンス)
が返されます。
例えば、引数として
data = [0 1 2 3 4 5 6]
と
sequence_length = 3
を指定すると
次のサンプルが生成されます。
[0 1 2], [1 2 3], [2 3 4], [3 4 5], [4 5 6]
それではデ-タ数を増やして具体的にプログラムを組んでみましょう。
import numpy as np
in_seq = np.arange(10)
とすると
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
が生成されます。
keras.utils.timeseries_dataset_from_array 引数
この関数を使うには
dummy_dataset = keras.utils.timeseries_dataset_from_array( )
[注)
dummy_dataset = tf.keras.preprocessing.timeseries_dataset_from_array( )
とする書き方もありますが Deprecated 非推奨になっている。
2020/2月 Keras 2.0 より]
として次の引数(配列)を渡す必要があります。
- data
処理したいデ-タ列を指定します。
data = in_seq
sequence_length = seq_lg(= 3)の数のデ-タ列を生成していくのですが、 ラスト3個のデ-タに対する目的値は存在しないので、ラスト3個の組のデ-タ列は生成されません。 - targets
目的値 targets 配列は data 配列にオフセット(seq_lg = 3)を足したものになります。
最初の目的値は in_seq[3] にあります。
よってここからスタ-トします。
targets = in_seq[seq_lg:]
ちなみに targets なしでも作成できます。
targets = None - sequence_length
ウィンドウ(シ-ケンス)の長さ(seq_lg = 3)を渡します。
sequence_length = seq_lg
- batch_size
これがなかなか!
よく分かりません。
適当です。
バッチサイズとは 1 回に計算するデータの数のことなのですが、
最大値は全学習データ数、今回の例では10個。
これよりもっと大きな数を指定しても大丈夫みたいです。
指定しなければデフォルトで 32。
一般的に2の累乗(2, 4, 8, 16 ・・・・)を指定しているようです。
バッチサイズを小さくすると、
局所解(もっと良い解が存在)に嵌りずらくなる。
使用するメモリ量が少なくなる。
収束も速くなる。
なので、少し小さめが良いようです。
この例では
batch_size = 2
とします。
ここまでで、
keras.utils.timeseries_dataset_from_array
の使い方を説明してきました。
引き続き、作成した dummy_dataset の内容を表示します。
70VPS に戻る




