Python Colaboratory
dummy_dataset の内容表示
ここまでで
keras.utils.timeseries_dataset_from_array
で dummy_dataset を作成しました。
引き続き、生成された dummy_dataset の中身を表示します。
これがなかなか難しい。
tensorflow 配列の中身を分かりやすく表示するには
TensorFlow ライブラリの Tensor.numpy() 関数
を使用して Tensor 配列 を NumPy 配列に変換してそれを表示するのが
簡単なように思います。
書式は、
**Tensor 配列**.numpy()
です。
今回の例では、dummy_dataset の中には
inputs 情報配列 [0 1 2] [1 2 3] と
targets 情報配列 [3 4]
の2種の配列が4組と余り1組が存在しています。
よって、まずは
dummy_dataset を inputs 配列と targets 配列
に分離します。
for inputs, targets in dummy_dataset:
その上で、テンソル inputs 配列、targets 配列をそれぞれ、NumPy 配列に変換して
それらを表示します。
print(inputs.numpy(), targets.numpy())
そうすると、batch_size = 2 ですから
2組の inputs 配列と2個の値からなる targets 配列が表示されます。
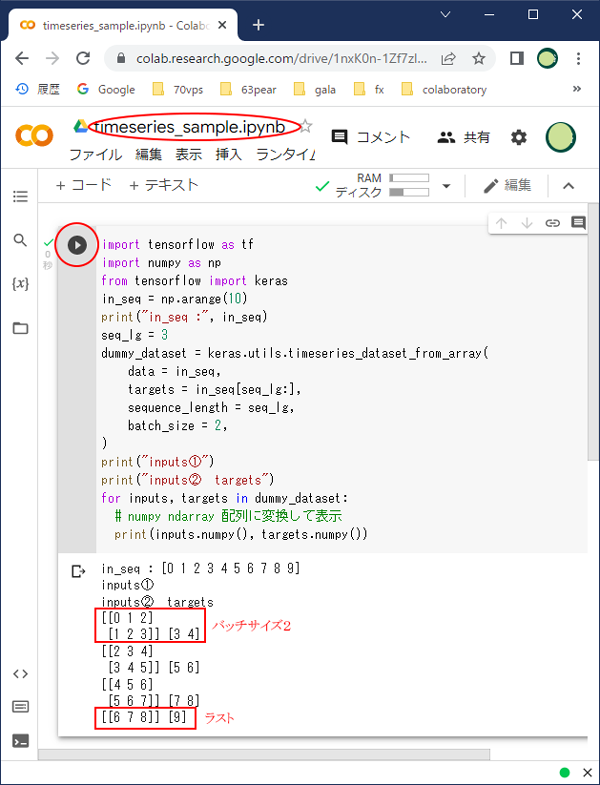
最初の表示は
[[0 1 2] [1 2 3]] [3 4]
となります。
そしてラストの表示は
[[6 7 8]] [9]
となります。
デ-タ数が10個で3個ずつの組を作ったので、ラストはバッチサイズを2にすることができず、1になりました。
ちなみに、targets なし targets = None にした場合は、
バッチサイズ2で4組の inputs 配列ができます。
[0 1 2] [1 2 3]
[2 3 4] [3 4 5]
[4 5 6] [5 6 7]
[6 7 8] [7 8 9]
timeseries_dataset ファイルまとめ
以上をまとめるとファイル内容は次のようになります。
import tensorflow as tf
import numpy as np
from tensorflow import keras
in_seq = np.arange(10)
print("in_seq :", in_seq)
seq_lg = 3
dummy_dataset = keras.utils.timeseries_dataset_from_array(
data = in_seq,
targets = in_seq[seq_lg:],
# targets = None,
sequence_length = seq_lg,
batch_size = 2,
)
print("inputs①")
print("inputs② targets")
for inputs, targets in dummy_dataset:
# numpy ndarray 配列に変換して表示
print(inputs.numpy(), targets.numpy())
ファイル名を timeseries_sample.ipynb として Colab の中で動かしてみましょう。
下図のようになれば OK です。
デ-タの標準化
ここまででは、デ-タは一律で極端なものはないものとして取扱いました。
でも実際のデ-タには、異常値が混じるのが普通です。
通常値の10倍ぐらいの値が混入してしまうと、RNN が精度よく動きません。
そこで、標準化を実施して、異常値を平準化します。
もし、デ-タ値の範囲が明確ならば正規化を行うことも可能です。
標準化は NumPy の mean, std 関数を使用すると簡単に求めることができます。
まずは、平均値を求めるのですが、
in_seq = np.arange(10)
として in_seq を生成したのでこのデ-タは INT 型になっているため、
このままでは平均値を求めることができません。
float16 型に変更します。
in_seq = np.arange(10, dtype='float16')
次に、元デ-タ in_seq が壊されないよう、コピした std_in_seq を作成します。
std_in_seq = in_seq.copy()
----
私は、PHP を経て Python を始めたので
std_in_seq = in_seq
として、嵌まった
in_seq も壊れてしまった
---
平均値 mean を求めます。
mean = np.mean(std_in_seq)
標準偏差σ std を求めます。
std = np.std(std_in_seq)
標準偏差値を計算します。
平均値からの差分をとります。
std_in_seq -= mean
std で割って各標準偏差値を求めます。
std_in_seq /= std
ここで、各標準偏差値を求める時の平均値について考えてみます。
標準偏差σ は各値から全体の平均値を引いても引かなくてもその値は変化せず同値です。
しかし、各標準偏差値は
① 平均値処理をするとき
各標準偏差値 = (各値-平均値)÷標準偏差σ
おおよそ、-1.5~ +1.5
② 平均値処理をしないとき
各標準偏差値 = 各値÷標準偏差σ
おおよそ、0~ +3
RNN では、活性化関数のことを考えると
0~+1 又は、-1~+1
になることが理想です。
正規化をすると 0~1 になりますが今回は標準化しますので、①が良いと言うことになります。
ここまで、デ-タの標準化について説明しました。
引き続き、標準化した dummy_dataset に作成し直します。
70VPS に戻る




