Python Colaboratory
CSV デ-タ timeseries_dataset 作成
ここまでで、keras.utils.timeseries_dataset_from_array を使用して
dummy_dataset を作成しました。
引き続き、ここまでの説明を元に CSV ファイル利用して
timeseries_dataset を作って行きたいと思います。
私が作成した、
周期が約20で、やや右肩上がりのあがりの三角波の CSV デ-タ
colab-data.csv
があります。
この CSV ファイルは
ここ
をクリックするとダウンロードすることができます。
Google Colaboratory で動かす Pythonプログラム のなかでファイルなどを読込みたい場合があります。
このようなときは、読込ませたいファイルを、あらかじめ Google ドライブにアップしておき、
そこから作成プログラムに読込みます。
まずは Google ドライブの \Colab Notebooks の中に \my_data を作成します。
□Colab Notebooks を右クリックして「新しいフォルダ」をクリック
my_data フォルダ (名前は適当です)
を作成します。
今回入手したファイル colab-data.csv
をファイルのアップロ-ド(右クリックで可能です)でこのフォルダに送出します。
この辺の説明は
CSV ファイルの読込
のなかでも同じようなことを説明していますので読み直してみてください。
CSV デ-タを利用した timeseries_dataset ファイル作成
それでは、CSV デ-タを利用した timeseries_dataset を構築するファイルを作成していきます。
CSV デ-タの読込みに必要なモジュ-ル類を import します。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
pandas を使用して colab-data.csv を読込みます。
このファイルは、フォルダ
drive/MyDrive/Colab Notebooks/my_data/
にあります。
よって
xl_df = pd.read_csv("drive/MyDrive/Colab Notebooks/my_data/colab-data.csv")
とすると xl_df に colab-data.csv の内容が読込まれました。
次に、Date 列を day に読込みます。
day = xl_df["Date"].values
pandas の DataFrame に対して ***.values のような形でアクセスすると、
NumPy ndarray 形式のデータを取得することができます。
このデ-タはこのあと使わないので、省略しても構いません。
そして Value 列を raw_data0 に読込みます。
raw_data0 = xl_df["Value"].values
値を表示してみましょう。
print(raw_data0.shape)
で各次元ごとの要素数をみてみると
(101,)
と表示され1次元のなかに 101個のデ-タがあることがわかります。
さらに
print(raw_data0)
とすると、0~100 の 101個のデ-タが横一行に並んでいます。
このデ-タを matplotlib でグラフ化してみてみましょう。
plt.plot(range(len(raw_data0)), raw_data0)
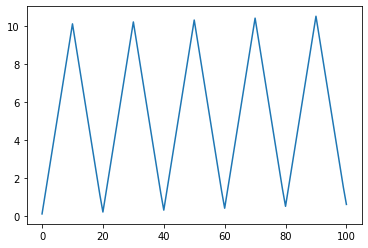
少し右肩上がりの三角波のような数値列であることがわかります。
これを見て人間ならば、101番目は、1 ぐらいかなと予測できます。
さて、RNN はどう予測するのかこのあとプログラムを作成していきます。
CSV デ-タの標準化
101個の CSV デ-タを標準化します。
標準化は NumPy の mean, std 関数を使用すると簡単に求めることができます。
まずは、平均値を求めます。
元デ-タ raw_data0 が壊されないよう、コピした raw_data を作成します。
raw_data = raw_data0.copy()
平均値 mean を求めます。
mean = np.mean(raw_data)
標準偏差σ std を求めます。
std = np.std(raw_data)
標準偏差値を計算します。
平均値からの差分をとります。
raw_data -= mean
std で割って各標準偏差値を求めます。
raw_data /= std
この内容を表示します。
print("各標準偏差値", raw_data)
print(raw_data)
引き続きここまでを整理し、
CSV デ-タ timeseries_dataset ファイルをまとめていきます。
70VPS に戻る



