Python Colaboratory
CSV timeseries_dataset まとめ
ここまでのところを一旦まとめます。
ファイル内容は途中ですが、次のようになります。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
xl_df = pd.read_csv("drive/MyDrive/Colab Notebooks/my_data/colab-data.csv")
day = xl_df["Date"].values
raw_data0 = xl_df["Value"].values
print("raw_data0.shape:", raw_data0.shape)
print("raw_data0")
print(raw_data0)
plt.plot(range(len(raw_data0)), raw_data0)
plt.show()
raw_data = raw_data0.copy()
# 行列の平均、標準偏差を求めます。
mean = np.mean(raw_data)
print("Mean", mean)
raw_data -= mean
std = np.std(raw_data)
print("Std ",std)
# 標準偏差値に変換
raw_data /= std
print("各標準偏差値")
print(raw_data)
それでは Colab の中で動かしてみましょう。
Colab 内の左上隅にある「ファイル」から「ノ-トブックを新規作成」をクリック。
上記ファイル内容をコピしてこれをノートブックの画面内のボックス(セル)のなかに
貼付け[Ctrl + v]ます。
画面上部のファイル名をクリックして、ファイル名を
keras-test-50.ipynb
に変更します。
ドライブのマウントをします。
左端にある「□」をクリックし、次にマウントマ-ク
 をクリックします。
をクリックします。
すると、マウントマ-クに「\」が入ります。
その後、▷ をクリックして動作させます。
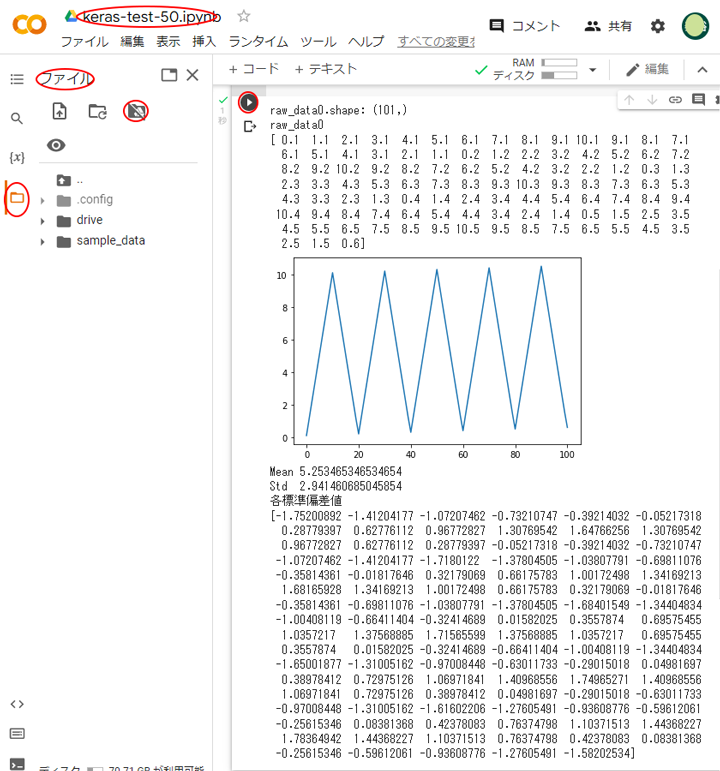
下記のようになれば OK です。
CSV デ-タ timeseries_dataset ファイル後半
CSV デ-タの標準化までができましたので、引き続き、
keras.utils.timeseries_dataset_from_array モジュ-ル
使用して timeseries_dataset デ-タを作成していきます。
必要なパラメ-タを設定します。
- sampling_rate
連続的にデ-タを使用する時は
sampling_rate = 1
とします。
例えば、一つおきに使用するときは、
sampling_rate = 2
とします。
今回は 1 を設定します。 - sequence_length
今回使用する colab-data.csv は 周期が約20で、やや右肩上がりのあがりの三角波のデ-タ です。
よって、20個のデ-タをひとまとまりとし、
sequence_length = 20
とします。 - delay
シ-ケンス(20個のデ-タまとまり)の目的値がどこにあるかを示す値です。
当然 20個の次にあります。
数式で表すと
delay = sampling_rate × sequence_length
となります。 - batch_size
適当に
batch_size = 32
とします。
どう適当なのかは RNN の理解-Ⅱ のなかの
keras.utils.timeseries_dataset_from_array 引数
batch_size
のところを読んでみてください。 - num_half_samples
CSV ファイルにあるデ-タ raw_data の数の半分の値を算出します。
num_half_samples = int(0.5 * len(raw_data))
今回はこの値を検証デ-タのスタ-ト値とします。
引き続き、3種の timeseries_dataset デ-タを作成していきます。
70VPS に戻る



