Python Colaboratory
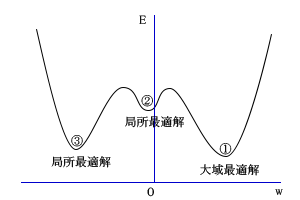
大域最適解みつからず
ここまでで、活性化関数について考えてきました。
引き続き、大域最適解について考察していきます。
勾配降下法で本当に大域最適解(真の値)を見つけることができるのでしょうか?
②③局所最適解と①大域最適解との関係がもし下図のようになっているとすれば
w をどこから探索を始めるかにかかってきて、的確に探し当てるのはいずれにせよ
無理ということになります。
活性化関数の選択
ここまで、活性化関数の例として tanh について説明してきました。
それではどんな活性化関数が使用できるのでしょうか?
代表的なものに
① 0 ~ +1 に活性化するもの
シグモイド関数(sigmoid function)
ReLU (Rectified Linear Unit)
LeakyReLU
② -1 ~ +1 に活性化するもの
tanh 関数
③ 活性化なし
linear
があります。
他にもいろいろあります。
入力値を正規化(min-max normalization)した場合には
①のReLU
入力値を標準化(z-score normalization)した場合には
tanh
あたりが良いと思います。
全結合モデル概要
RNN で最も単純で計算量の少ないモデルを作成します。
軽量なモデルとは言うものの非常に強力な能力があります。
今回のモデルを図示すると下図のようになります。
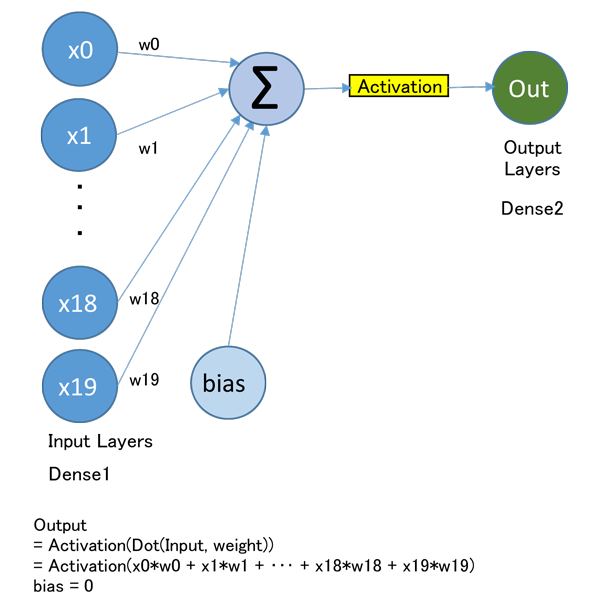
全結合モデル作成
それではモデルを作成していきます。
- モジュ-ル
必要なモジュ-ルは3つです。
from tensorflow import keras
from keras import layers
from keras import initializers
- Input 宣言
inputs = keras.Input(shape=(sequence_length,))
input デ-タの配列がどんな型式になっているか宣言します。
今回は、sequence_length=20 個の配列が入力されると宣言しています。
この inputs オブジェクトには、このモデルが処理するデ-タの形状とデ-タ型に関する情報が 含まれています。
このようなオブジェクトをシンボリックテンソルと呼びます。
シンボリックテンソルとは、実際のデ-タは含んでいないテンソルのことであり、 モデルを使うときにモデルに渡される実際のテンソルの仕様を定義しています。
- batch_size 問題
あの適当に決めた batch_size 値がここで問題になってきます。
Input される train_dataset は batch_size=32 ごとに配列のなかで分割されています。
20×32 + 20×32 + 20×16
となっているのでこれを
20×80
の形に変更しないと FunctionalAPI を使うことができません。
x = layers.Flatten()(inputs)
としてデ-タを平坦化します。
全結合モデル作成の前半が完成しました。
引き続き、後半部分を作成します。
70VPS に戻る




